约 1589 个字 47 行代码 4 张图片 预计阅读时间 9 分钟 共被读过 次
RISC-V汇编与编译链接流程总结¶
函数调用与堆栈管理¶
调用约定(Calling Convention)¶

- Caller责任:
- 保存临时寄存器(如
a0-a7,t0-t6) - 传递参数到
a0-a7,返回值通过a0返回 - Callee责任:
- 保存被调用者保存寄存器(如
s0-s11) - 通过栈帧管理局部变量
栈帧操作¶
Text Only
map:
addi sp, sp, -16 # 分配栈空间(16字节)
sw ra, 0(sp) # 保存返回地址
sw s0, 4(sp) # 保存s0
mv s0, a0 # 将参数a0(lst)保存到s0
...
postamble:
lw ra, 0(sp) # 恢复返回地址
addi sp, sp, 16 # 释放栈空间
ret # 返回(等价于jalr x0, ra, 0)
说明:函数入口分配栈空间保存寄存器,出口恢复寄存器并释放栈空间。
寄存器用途与保存规则¶
| 寄存器类型 | 示例 | 保存责任 |
|---|---|---|
| 临时寄存器 | t0-t6 | Caller保存 |
| 保存寄存器 | s0-s11 | Callee保存 |
| 参数寄存器 | a0-a7 | Caller保存 |
| 返回地址 | ra | Caller保存(需显式保存) |
关键指令与伪指令实现¶
条件分支与跳转¶
| 伪指令 | 实际指令 | 说明 |
|---|---|---|
j label | jal x0, label | 无条件跳转 |
ret | jalr x0, ra, 0 | 从函数返回 |
bnez rs, L | bne rs, x0, L | 非零跳转 |
尾递归优化(Tail Call)¶
-
代码约定:
- 这里定义了一个函数
foo,它接收一个整数参数,并在某些计算后返回对自身的递归调用。这种调用被称为尾递归。尾递归的特点是当前函数在调用另一个函数之前不需要做任何额外的工作。
2. 参数评估与寄存器分配: - 在执行尾递归调用之前,先计算传给
foo的参数,并将这些参数放到特定的寄存器(如a0到a7)中。这是为即将发生的函数调用准备数据。
3. 直接跳转而非调用: - 通常情况下会使用跳转指令(jump),而不是标准的子程序调用指令来进入新的函数调用。这避免了创建新的栈帧。
4. 跳过前导部分: - 由于已经处于同一个函数上下文中,可以直接复用现有的返回地址(ra)和其他保存的寄存器内容,而不需要再次设置它们。这样就节省了空间和时间。
5. 直接返回: - 经过优化后的尾递归调用,
foo可以直接返回到最初调用它的位置,而不需要层层返回。
6. 减少寄存器恢复: - 通过这种方式,减少了不必要的寄存器恢复操作,进一步提高了性能。
总结来说,尾递归优化允许编译器识别出尾递归模式,并将其转换成循环结构或更高效的跳转机制,从而避免了每次递归调用都增加新的栈帧所带来的开销。这种优化对于防止栈溢出以及提升性能非常有用,尤其是在深度递归场景下。
- 这里定义了一个函数
编译链接流程¶
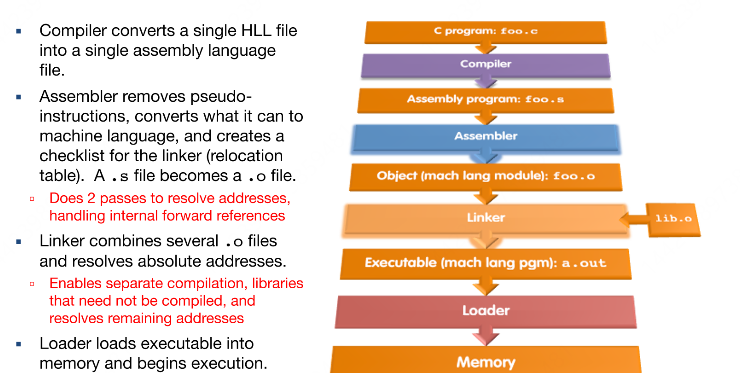
四阶段流程¶
- 编译:C → 汇编(
.s)
- 处理伪指令(如la分解为auipc+addi) - 汇编:汇编 → 目标文件(
.o)
- 生成符号表与重定位表 - 链接:目标文件 → 可执行文件(
a.out)
- 合并代码段与数据段,解析外部符号 - 加载:可执行文件 → 内存
- OS分配地址空间,初始化寄存器与栈

符号表与重定位表¶
Question
如果程序需要跳转到其他文件的位置,这些文件的位置不是相对当前位置的偏移量所能确定的
我们需要创建两个表格来帮助处理这个问题
| 表类型 | 内容 |
|---|---|
| 符号表 | 全局符号(symbol)地址(函数. text 里面 /数据. data 里面) |
| 重定位表 | 需要修正的指令地址 |
链接¶
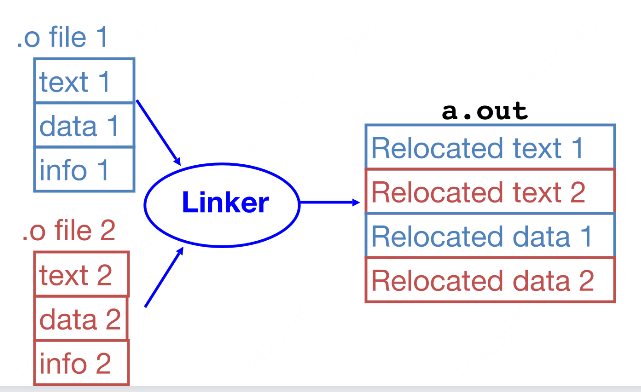
- 从每个目标文件(.o 文件)中提取文本段并将它们合并在一起
- 从各个目标文件中取出代码所在的文本段,然后把这些文本段按一定顺序组合到一块。
- 从每个目标文件中提取数据段,将它们合并在一起,并把合并后的数据段连接到文本段的末尾
- 每个目标文件中除了代码的文本段,还有存储数据的数据段。先把所有目标文件的数据段提取出来合并,然后将这合并好的数据段添加到前面合并好的文本段后面。
- 解析引用
- 遍历重定位表:重定位表记录了目标文件中需要在链接时进行调整的信息,比如一些符号引用的位置。遍历这个表,对每一个表项进行处理。
- 填充所有绝对地址:通过处理重定位表中的表项,将程序中使用的相对地址或者符号引用替换为最终运行时的绝对地址,使得程序在运行时能够正确地访问到所需的代码和数据。
总体来说,这是链接器在将多个目标文件链接成一个可执行文件过程中的关键步骤,通过这些操作把各个独立编译生成的目标文件整合为一个完整的、能够在目标系统上运行的可执行程序 。
动态链接与静态链接¶
| 特性 | 静态链接 | 动态链接 |
|---|---|---|
| 空间效率 | 包含所有库代码,体积大 | 共享库,体积小 |
| 更新维护 | 需重新编译 | 替换库文件即可 |
| 内存占用 | 独立进程占用高 | 共享库减少内存冗余 |
代码示例¶
递归函数map的RISC-V实现¶
Text Only
map:
addi sp, sp, -16
sw ra, 0(sp)
sw s0, 4(sp)
mv s0, a0 # lst存入s0
bnez s0, else
li a0, 0 # 返回NULL
j postamble
else:
li a0, 8
call malloc # 分配内存
mv s2, a0 # newcell存入s2
lw a0, 0(s0)
jalr ra, s1 # 调用f(lst->car)
sw a0, 0(s2) # newcell->car = f(...)
lw a0, 4(s0)
call map # 递归调用
sw a0, 4(s2) # newcell->cdr = map(...)
postamble:
lw ra, 0(sp)
addi sp, sp, 16
ret
逻辑:递归遍历链表,对每个节点应用函数f,生成新链表。
乘法与除法指令¶
Text Only
# 推荐的使用习惯
mulh s1, s2, s3 # 高32位乘积
mul s0, s2, s3 # 低32位乘积
div s0, s2, s3 # 商
rem s1, s2, s3 # 余数
说明:RISC-V乘法指令生成64位结果需两条指令( mulh + mul )。
可供选择的😎RISCV-16bits 压缩ISA¶
- 不是完整实现的ISA
- 是最常用的指令集的优化
- 小立即数
- 常用寄存器(x0, ra/x1, sp/x2)
- 相对于栈指针加载字/存储字
- 6位立即数是字对齐的且进行零扩展:仅允许正偏移量
- 有效地将序言/结语的大小削减了50%
- 常用寄存器加载/存储(s0 - s1,a0 - a5)
- 5位立即数,同样是字对齐且零扩展:常见的数组/结构体访问模式
- 带有11位立即数的跳转/带链接跳转
- 将链接写入x0或ra
- 条件分支