约 907 个字 20 行代码 4 张图片 预计阅读时间 5 分钟 共被读过 次
计算机体系结构 - 缓存(Caches)总结¶
缓存基础¶
缓存行(Cache Line)¶
- 定义:缓存的最小数据单元,大小为32字节(示例中)。
- 行为:若访问未命中,将整个缓存行从主存加载到缓存。
地址解析¶
- 地址组成(8位地址示例):
- 字节偏移量:
log2(32) = 5 bits(32字节行大小)。 - 索引位:
log2(行数),如4行 → 2 bits。 - 标签位:剩余高位地址(如8位地址 → 3 bits标签)。
缓存类型¶
全关联缓存(Fully Associative)¶
- 结构:任意行可映射到任意缓存位置。
- 标签匹配:并行比较所有行的标签。
- 优缺点:
- ✅ 无冲突(空间充足时)。
- ❌ 硬件开销大(需大量比较器)。
直接映射缓存(Direct Mapped)¶
- 结构:地址索引唯一确定缓存行。
- 示例:地址
0b01100000映射到索引0。 - 优缺点:
- ✅ 硬件简单(仅需一次比较)。
- ❌ 高冲突率(不同地址可能映射同一索引)。
组相联缓存(Set-Associative)¶
- 结构:缓存划分为组,每组含多个路(如2-way)。
- 行为:地址索引确定组,标签匹配组内任意路。
- 替换策略:LRU(Least Recently Used)位跟踪使用情况。
- 优缺点:
- ✅ 冲突率低于直接映射。
- ❌ 硬件复杂度高于直接映射。
缓存性能分析¶
平均内存访问时间(AMAT Average Memory Access Time)¶
- 公式:
\(AMAT = Hit Time + Miss Rate × Miss Penalty\) - 多级缓存公式:
AMAT = L1 Hit Time + L1 Miss Rate × (L2 Hit Time + L2 Miss Rate × L2 Miss Penalty)
示例计算¶
Text Only
单级缓存:
Hit Rate = 90%, Hit Time = 4 cycles, Miss Penalty = 20 cycles
AMAT = 4 + 0.1×20 = 6 cycles
两级缓存:
L1 Hit Rate = 60%, L1 Hit Time = 5 cycles
L2 Hit Rate = 95%, L2 Hit Time = 8 cycles, L2 Miss Penalty = 40 cycles
AMAT = 5 + 0.4×(8 + 0.05×40) = 9 cycles
参数对AMAT的影响¶
| 参数 | 关联性变化影响 | 条目数变化影响 | 块大小变化影响 |
|---|---|---|---|
| Hit Time | 随关联度增加而上升 | 随条目数增加而上升 | 基本不变 |
| Miss Rate | 随关联度增加而下降 | 随条目数增加而下降 | 先降(空间局部性)后升(冲突增加) |
| Miss Penalty | 基本不变 | 不变 | 随块大小增加而上升 |
编程优化技巧¶
数组步长(Stride)¶
- 关键问题:步长过大导致缓存行利用率低。
- 示例代码:
C
int sum_array(int *my_arr, int size, int stride) {
int sum = 0;
for (int i = 0; i < size; i += stride) {
sum += my_arr[i]; // 步长影响缓存命中
}
return sum;
}
- 缓存行为(行大小16字节,int=4字节):
stride=1:每行加载4个int,全命中。
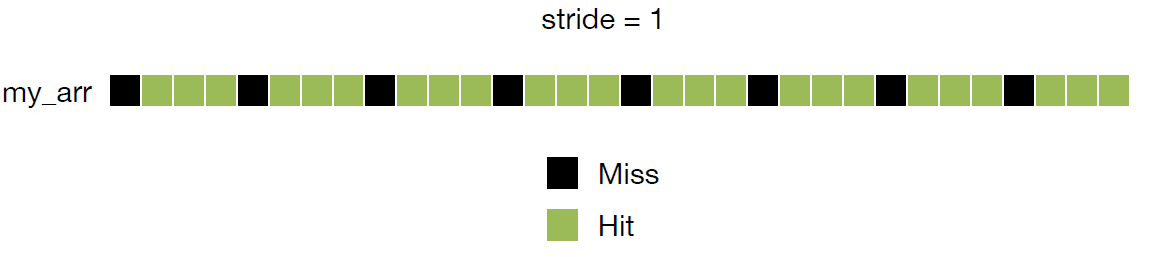
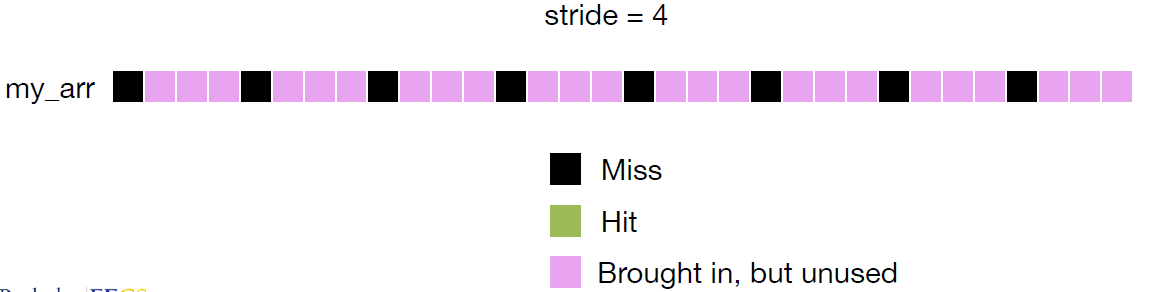
stride=4:每次访问不同行 → 高未命中率。
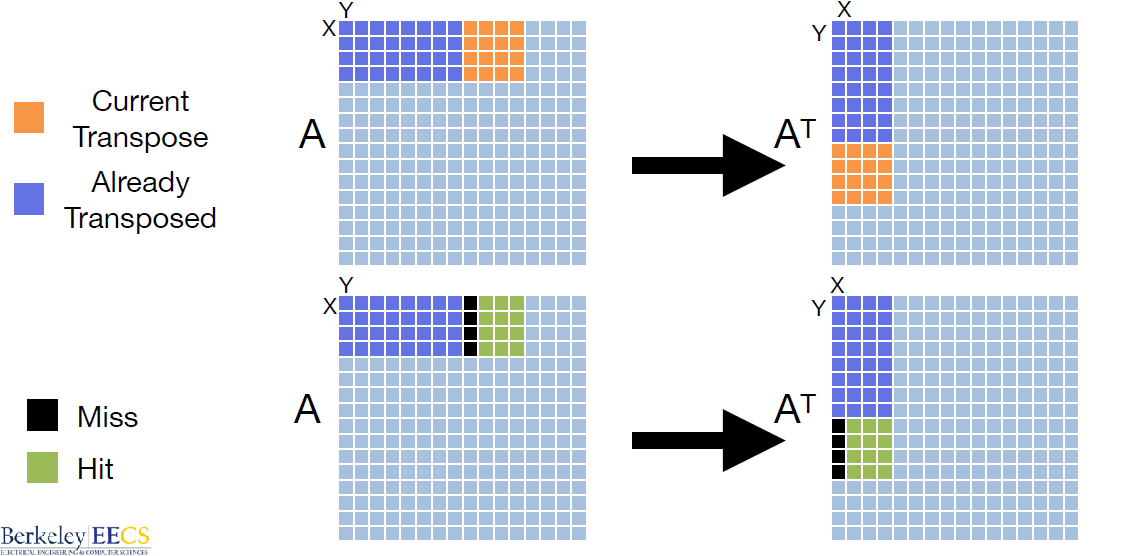
矩阵转置(Cache Blocking)¶
- 目标:改善空间局部性,减少缓存冲突。
- 行为:按块转置矩阵,使连续访问同一缓存行。
- 示例:
- 原矩阵按行存储,转置后按列访问 → 缓存未命中率高。
- 分块转置后,块内数据连续 → 缓存利用率提高。
内存层次结构¶
多级缓存¶
以 L2 缓存为例
- L2 比 L1 大
- 导致 L2 的更高的 hit rate
- 所有 L1 中的 data 在 L2 中都能够找到
- 如果 L1 中的 cache block 是 dirty 的,当其被冲突掉时,你需要更新其在 L2 中的备份
| 层级 | 特点 |
|---|---|
| L1 | 速度最快,容量最小(32KB),集成在CPU内 |
| L2 | 容量较大(256KB),降低L1未命中惩罚 |
| L3 | 共享缓存(4MB),进一步降低未命中惩罚 |
局部与全局命中率¶
- 局部命中率:本级命中次数 / 本级访问次数。
- 全局命中率:本级命中次数 / 总访问次数。
实际示例(Intel Core i7-6500U)¶
- L1缓存:32KB,8-way,4周期延迟。
- L2缓存:256KB,4-way,12周期延迟。
- L3缓存:4MB,16-way,34周期延迟。

Text Only
查看缓存信息命令:
- Linux: `lscpu`
- macOS: `sysctl -a hw machdep.cpu`
- Windows: `wmic memcache list brief`
总结重点:缓存性能优化需平衡关联度、块大小和条目数,编程时关注数据访问模式(如步长、矩阵分块)以提升局部性。